
In this session, we’ll build your intuition for probability, the normal distribution, p-values, Type I/II errors, and statistical power — using examples rooted in clinical optometry. We'll even sketch some Gaussian curves along the way!
Probability is a measure of uncertainty. In clinical work, we often ask things like:
Probability is a number between 0 and 1. If you flip a fair coin, the chance of heads is 0.5. If 60% of a population have a spherical equivalent (SE) below −0.50 D, then:
# Probability estimate in R
p_myopia <- 0.60
p_not_myopic <- 1 - p_myopia
The normal distribution — aka the bell curve — is everywhere in vision science. It models things like intraocular pressure, visual acuity scores, and refractive errors.
# Simulate a normal distribution of refraction values
set.seed(123)
refraction <- rnorm(1000, mean = -1.00, sd = 1.5)
hist(refraction, breaks = 30, col = "lightblue", main = "Refraction in Young Adults", xlab = "Diopters")
The p-value is the probability of getting a result this extreme if the null hypothesis were true. A small p-value (typically < 0.05) suggests that your result is unlikely due to random chance.
# One-sample t-test: Is mean refraction different from emmetropia (0 D)?
t.test(refraction, mu = 0)
Alpha (α) is the threshold for a "rare" result. Usually, α = 0.05 (5%). That means:
| Null True | Null False | |
|---|---|---|
| Reject Null | Type I Error (α) | Correct (Power) |
| Fail to Reject Null | Correct | Type II Error (β) |
Type I error (α): False positive
Type II error (β): False negative
Power: 1 − β — the probability you’ll detect a real effect when it exists.
If you’re trying to detect a difference in refractive error, your ability to detect it depends on:
# Power analysis
library(pwr)
pwr.t.test(d = 0.5, power = 0.8, sig.level = 0.05, type = "two.sample")

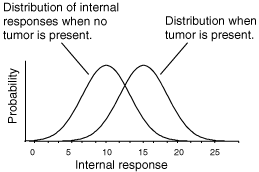
Your visual system performs constant hypothesis testing: Is this edge real, or is it noise? Signal detection theory gives us:
This is especially relevant in low-contrast vision tests or glaucoma screening.
Statisticians love to argue, and the most famous showdown is between Frequentist and Bayesian views of evidence.
| Frequentist | Bayesian |
|---|---|
| Probability = long-run frequency of an event | Probability = degree of belief, based on prior and data |
| p-values test how surprising the data is, assuming the null is true | Updates your belief in a hypothesis after seeing data |
| Does not assign probability to hypotheses | Directly computes probability of a hypothesis |
Example: You test a new contact lens for reducing dryness.
In this lab, you’ll compare traditional (Frequentist) and Bayesian approaches to evaluating evidence, using real-ish data from a sample of young adults with varying levels of myopia.
Question: Is the average spherical equivalent (SE) significantly different from emmetropia (0 D)?
Download Dataset (CSV)install.packages(c("BayesFactor", "ggplot2", "bayestestR"))
We’ll use a one-sample t-test to see if the group’s mean SE differs from 0 D (emmetropia).
# Load and inspect data
df <- read.csv("myopia_study_data.csv")
summary(df$SE)
# Frequentist t-test
t.test(df$SE, mu = 0)
This time, we ask: What is the probability that the true mean differs from 0 D, given our data and prior beliefs?
library(BayesFactor)
# Bayesian one-sample t-test
bf_result <- ttestBF(x = df$SE, mu = 0)
print(bf_result)
Interpret the Bayes Factor (BF₁₀):
Now let’s see what the Bayesian test thinks about the most credible values of the mean SE.
library(bayestestR)
# Visualize posterior
posterior <- estimate_density(bf_result)
plot(posterior, main = "Posterior Distribution of Mean SE")
# Highest Density Interval (HDI)
describe_posterior(bf_result)
# Simulate new sample with mild myopia
sim_data <- rnorm(40, mean = -0.75, sd = 1.2)
t.test(sim_data, mu = 0)
ttestBF(x = sim_data, mu = 0)
How does a smaller sample or effect size impact your inference? What does the Bayesian method still offer here?
| Frequentist | Bayesian |
|---|---|
| Controls false positive rate | Gives probability of hypothesis |
| p-value says how rare the data is under H₀ | BF quantifies how much evidence supports H₁ over H₀ |
| No prior knowledge used | Incorporates prior beliefs |
Both are useful. You’ll see them side by side in future research papers — so get comfy with both!